My Skills
My Projects

V-RAG: Video-based Retrieval Augmented Generation for Lifelike Conversational AI
I designed a multimodal video-based Retrieval-Augmented Generation (RAG) pipeline to address a key challenge in traditional systems: the loss of context and visual detail during repetitive captioning stages. By integrating tools like VideoDB, LlamaIndex, Whisper, and VideoLLaVa into a microservices architecture, we created a system capable of delivering context-rich, visually-aware responses with incredible efficiency. One of our biggest achievements was achieving semantic retrievals in just 3 seconds for 20-second video clips using open-sourced LLMs.
When designing the pipeline, I wanted to solve a problem on conventional multimodal RAG systems, which often lose vital visual details. To address that, my pipeline preserves and enhances context by enabling two-way, reversible video-to-text and text-to-video transformations. The workflow processes input videos to generate and query metadata, retrieves and resamples keyframes, and feeds this information into a language model to produce enriched responses. By simulating human-like memory encoding, storing visuals, sounds, and contextual details enables the pipeline to deliver more nuanced and adaptive interactions.
This approach is especially impactful in healthcare, where lossless keyframe resampling ensures no critical visual detail is overlooked, making it invaluable for diagnostics and training. Reuniting with my team from the Cantcer project, we focused exclusively on open-source tools, showcasing how far open-source AI has come. Ultimately, this pipeline represents a step forward in creating lifelike, context-aware AI systems for healthcare, conversational assistants, and beyond.
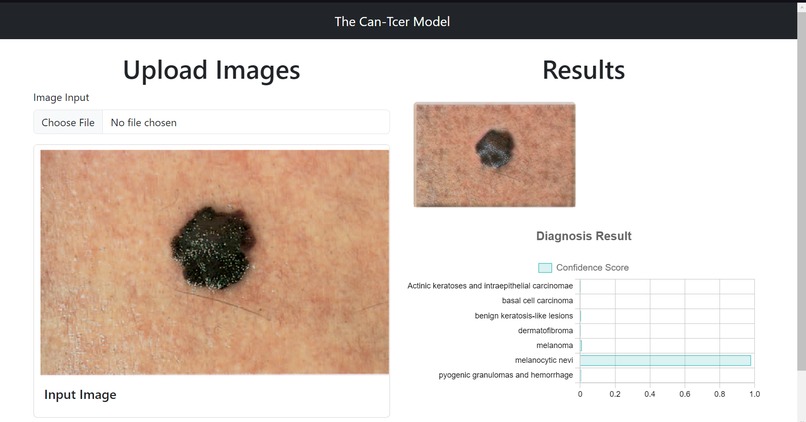
CanT-cer: Pioneering Skin Cancer Data Generation to Combat AI Bias
As the Fullstack developer, I helped develop a web app to address the need for synthetic medical datasets of diverse skin tones in cancer diagnosis, utilizing flask and Google Colab to deploy custom AI model pipelines for skin lesion classification, segmentation, and style transfer.
I also streamlined an Express RESTful API architecture to facilitate data transmission.
I implemented server-sided image encoding, file bundling and compression, enabling efficient exports of generated datasets in .ZIP format.
Furthermore, I integrated server responses into a React and Bootstrap UI.
I also succesfully deployed the web service on Google Cloud App Engine.
Overall, it was a great learning experience for web development.
Awarded Best use of Google Cloud by Major League Hacking (MLH) in MadHacks Fall 2023

Cornucopia: Uniting Small-Scale Farmers With Community Supported Agriculture (CSA)
As the Full-Stack Developer for "Cornucopia," I played a role in creating a web application that connects small-scale farmers with local markets through a Community Supported Agriculture (CSA).
Utilizing React and Next.js, I crafted an intuitive interface with Tailwind CSS for easy navigation.
My key contributions included integrating a lasso regression model to recommend optimal crop prices,
employing MongoDB Atlas for real-time inventory and logistics management, and overcoming the team's web development learning curve by promoting parallel development, by leading the implementation of skeletal React component hierachies and state management.
It provided me a solid foundation as a first-time React user! Additionally, I enhanced user engagement by incorporating a Leaflet API-powered interactive map for efficient delivery logistics.
Our innovative work was recognized with the Best Agricultural Innovation Award at HACKUIOWA 2023.
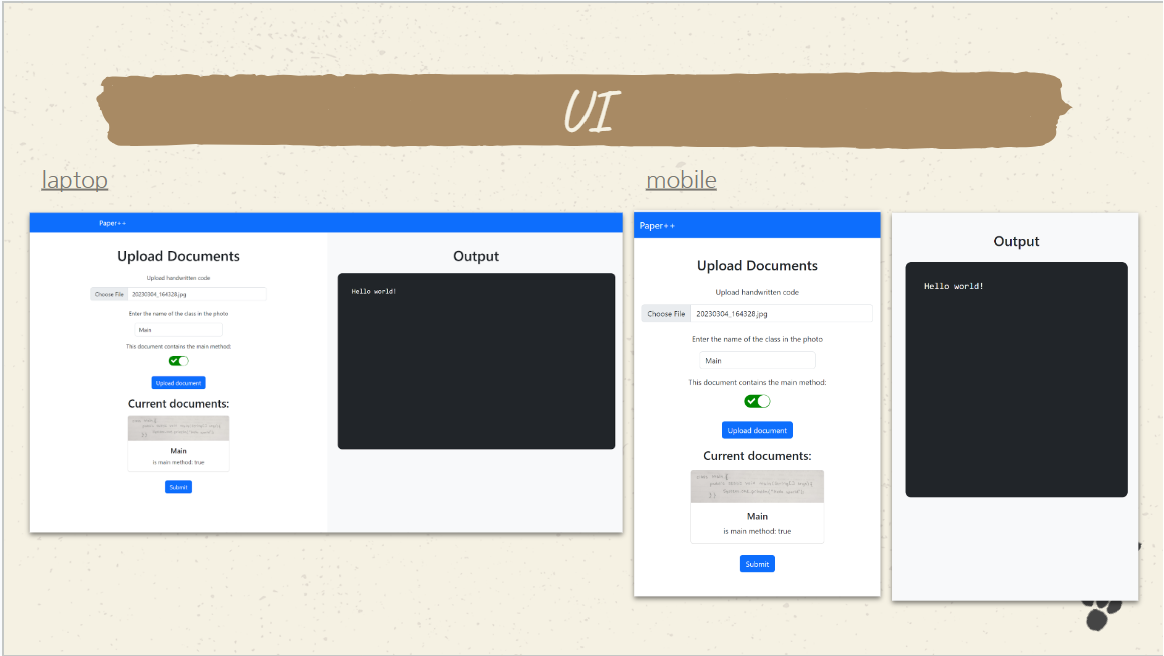
Paper++: Redesigning Academia and Paper-based Code Examinations
For Paper++, I utilized the Google Cloud Vision API to transform handwritten code from images into compilable and executable programs,
addressing a niche need in academic and professional settings.
This system supports user programs with static dependencies, offering a seamless transition from paper to a digital platform of a remote code execution system.
The project aims to streamline the grading process for paper-based code assessments and interviews.
I developed a Java backend to manage the automatic, thread-synced compilation and execution
of these programs, integrating the outputs into a React-based UI.
This project introduced me to leetcode's architecture with how I could improve Paper++ to become scalable. I hope to revisit this project and implement
a stateless architecture, using Docker compose for Boss-Worker nodes and load balancing.
Our efforts were recognized at MadHacks 2023,
where "Paper++" was ranked in the top 5 out of 58 projects,
validating the project's potential to modernize the evaluation of coding skills.

College Database: A Red-Black Tree approach to stable O(log n) data storage operations
This database utilizes Red-Black Trees for stable and efficient insertion, lookup, and deletion operations written in Java. It was aimed to
provide a streamlined and highly customizable platform for managing data on over 800 colleges.
In a team of 4, I developed a CSV parsing module to extract and filter college data according to specified priorities during
insertion.
I also enhanced the database with the ability to perform dynamic lookups based on various data fields, including but not limited to
rankings, student populations, and academic programs.
This was an exploratory (and bad) approach to simulate a schema-less pseudo NoSql Database,
by using Java reflection to retrieve values and data types during runtime,
and invoking its appropriate Comparable method. I also explored and implemented the O(log n) algorithm for deletion operations.